
Per-story estimates were an interesting experiment that failed and it’s time to move on. Today, we have better ways so it’s time to stop putting individual estimates on stories. This is equally true for Scrum and Kanban teams.
Let’s look first at why we put estimates on stories at all.
- “This is what we’ve always done.” : The most unsatisfying answer and yet a common one. Your team is supposed to be improving over time. That means re-evaluating practices you’ve been doing to see if they’re still serving you well. This one isn’t.
- “We were told estimating was a best practice.” : There was a time that the agile community thought this was true, but that was a long time ago. It was a great experiment that we learned from, and over time we found better ways. It’s time to move on.
- For a scrum team: “We want to determine how much will fit in the next sprint.” : It turns out that counting stories is just as accurate and is a lot less effort. If we completed 6 stories in the last sprint then we’ll sign up for 6 in the next.
- “We want to know when we’ll be done this larger piece of work that’s made up of many stories.” : This is still a valid need, however there are better ways to get that answer. See below.
There are two fundamental problems with estimates. The first is annoying and the second is a showstopper.
- They’re time consuming to create, taking time away from actually delivering new features.
- They’re never accurate. When we analyze the data, there is never a correlation between the estimate and the actual time it takes to get the work done.
Let’s dig into that second one. The chart below is typical of a development team. Estimates on the Y axis and the actual cycletime on the X axis. We can clearly see that there is no correlation between the two. Items estimated at two story points are taking anywhere from two to nine days.
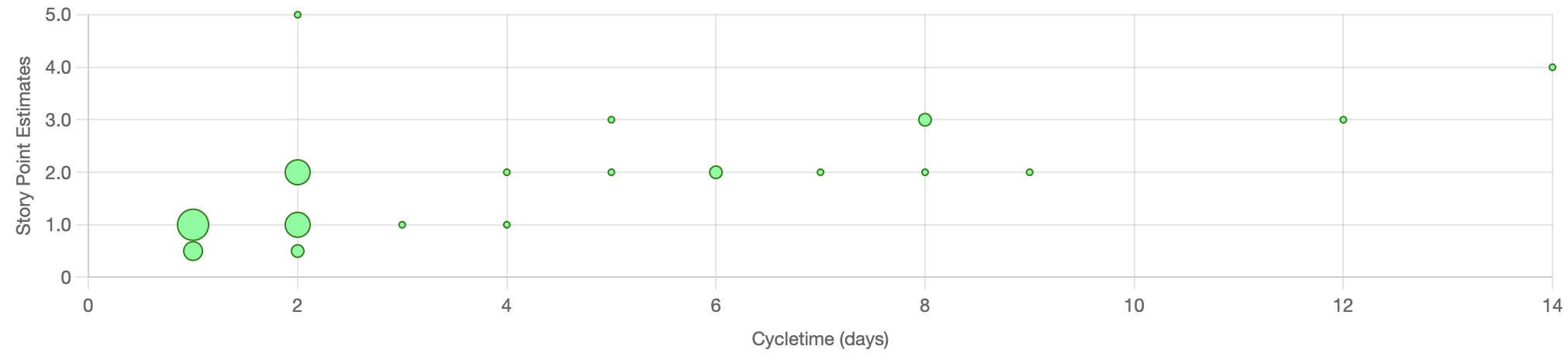 Chart generated with the Jira Metrics tool.
Chart generated with the Jira Metrics tool.
I’m sure right now you’re thinking ‘But my team is different - our estimates are very accurate”. I graph this data with every single team I coach and I have never seen a strong correlation from any of those teams. If you’re convinced that your team is different then I encourage you to graph your own data.
With such wild variation in the estimates, it’s impossible to do any of the prediction above. We can’t even determine how many story points will fit in the next sprint, let alone how much can we complete in the next six months.
So what can we do?
We could try to get better at estimating but frankly, that’s not a good use of our time. The science shows that humans are inherently bad at estimates1 so there’s a limit to how much we can improve here.
A better solution would be to find alternate ways to get the answers we want.
If you want to know “how long it will take to complete these hundred stories”, or the opposite “how many stories can I complete by October 1” then use Probabilistic Forecasting. This will yield significantly more accurate results with a fraction of the effort. More accurate for less effort is always a win.
Probabilistic forecasting uses historical data to make forecasts about future behaviour. We’ll be able to say that with 85% certainty, we can complete these 100 items in 79 days or less. It’s probabilistic, because we’re providing a likelihood (85%) and a range (79 days or less). This is the same way that we provide forecasts for weather.
Shameless plug: We teach a two day deep dive into probabilistic forecasting in the Applying Metrics for Predictability course. See our training page for upcoming public classes, or ask about private classes.
Many people seem to conflate talking about the story with the process of estimation. I frequently hear “If we don’t estimate the story then we won’t know everything that’s involved.” To be clear, I’m not suggesting even for a moment that you shouldn’t talk about the story. I’m saying that putting a number on it is a waste of everyone’s time.
Other articles on forecasting on this site: